Digital video compression algorithms exist to preserve the perceptual quality of an input digital video signal, while at the same time reducing the quantity of data necessary to reproduce it. The algorithms that this paper considers are aimed at this objective. Since humans are the consumers of the end result of video compression, by considering human visual perception, irrelevant information can be discarded without a corresponding loss in perceptual quality. Perceptual Video Encoding merges the ideas of digital video compression algorithms and visual perception of quality. Contextual Video Encoding (CVE) is a proposed type of Perceptual Video Encoding which incorporates factors of a video's viewing environment into the video encoding framework. CVE is an algorithm based on the removal of spatial frequencies of an image depending on user proximity to a video display. The following paper describes how CVE could be implemented alongside existing video encoders in use today by reviewing current literature in the field.
This paper was written in December 2019 as a senior thesis for my Bachelor's Degree in Computer Science. When I finished my degree I implemented a PNG still-image encoder based on several concepts that were covered in the paper. I wrote the encoder in C# since I was applying for jobs as a software developer and most of the positions that I applied for were looking for C# programming skills. Since completing this paper I transitioned from working as an Aerial Camera Operator for a major news television network in Philadelphia to working as a Full Stack Web Developer. Today I work on Learning Management Systems, developing Spring Boot/Java back-end applications with the front-end written in Angular/Typescript. I am currently in the process of developing this website, expanding the research paper that you are currently reading, and working on a Java rewrite of version 1.0 of my encoder to accompany this paper.
Introduction
An uncompressed digital video signal starts out as a sequence of numbers, each of which denote a level of light intensity for a given spatial region of a still image, called a pixel. Each number in the sequence can be described by the inequality, 0 ≤ s ≤ 255 , where a shade, s, is an integer that can range from 0 (black) to 255 (white) and any shade of gray between these two values. This code is sufficient to describe a black and white image and also any monochromatic image, where the variable, s, describes shades of a single color. To reproduce all possible colors in the visible spectrum, and thereby create a polychromatic (color) image, it is necessary to represent a pixel using three distinct shades of a single color. "The component theory (trichromatic theory) of color vision... [holds] that any color of the visible spectrum can be matched by a mixing together of three different wavelengths of light in different proportions" (Pinel, 2014, p. 148). The RGB Color Model reproduces colors by adding together shades of the primary colors: red, green, and blue. Using this model and 256 shades of each primary color, a total of: 256 * 256 * 256 = 16,777,216 distinct colors can be represented. "For example, the color magenta is an equal mix of pure red and blue, which would be encoded as (255, 0, 255)"(Schneider, 2013, p. 169).
An image's resolution, or area, is composed of a certain number of pixels that make up the image's length multiplied by a number of pixels that make up the image's height. Collectively, this rectangular group of MxN pixels is perceived as a single image from a certain distance. The Principle of Proximity under the Gestalt Principles of Perceptual Organization confirms what can be observed with the human sense of sight: a group of objects, in this case pixels, is perceived as a single object; an image. The idea is that, "Things that are near each other appear to be grouped together" (Goldstein, Brockmole, 2017, p. 101). A still image in a video is called a frame, which can be defined as a sequence of integers which denote a rectangular array of pixel values from left to-right and top-to-bottom.
Fig-2: Zoomed in to Fig-1 to show individual pixels
The idea of an array of pixels, or frame, being perceived as a single object is important to establishing why humans perceive motion in a video. There is no actual motion in a video, but there is Apparent Movement, which is, "An illusion of movement that occurs when two objects [frames] separated in space are presented rapidly, one after another, separated by a brief time interval" (Goldstein et al., 2017, p. 395). A video is composed of a series of frames, perceived as objects, that are displayed to a viewer fractions of a second apart. When frames are displayed in this manner, it creates the illusion of movement even though there is no actual movement. The perception of what is taking place when a video is viewed by a human observer, in terms of how pixels are grouper and movment, is very different from reality.
In summary, the Trichromatic Theory, the Gestalt Principle of Proximity, and Apparent Movement all describe ways human beings perceive a digital video. It demonstrates the interaction of two systems: the natural, Human Visual System (HVS), and artificial, electronic computer systems. Although both digital video cameras, including their on-board computers, as well as the Fig-1: Complete video frame Fig-2: Zoomed in to Fig-1 to show individual pixels. human eye transduce light into electrical signals and process this spatiotemporal data, these three ideas begin to demonstrate how different the HVS is from computers. "Transduction is the conversion of one form of energy to another. Visual transduction is the conversion of light to neural signals by the visual receptors" (Pinel, 2014, p. 139). Instead of neural signals, digital video cameras produce a stream of discrete data values which represent light intensity using numeric codes. "A code is a system of symbols (letters, numbers, bits, and the like) used to represent a body of information or set of events" (Gonzalez, 2018, p. 540). Using this code, a computer can store and display an exact representation of what was recorded to some degree of precision at some time in the future. A video contains spatiotemporal data: space, in the form of an array of light intensities in the area of a frame, that changes with respect to time. Data in this form allows an artificial computer system to communicate with the natural, Human Visual System, using visible light in the electromagnetic spectrum. The HVS interfaces with the artificial system in this way. Human visual perception, therefore, is an indispensible part of any discussion of digital video systems and will be considered along with it.
Perceptual Quality and Entropy Coding
The problem with a code that uses three bytes of data to represent a pixel, where 1920x1080 pixels is a common frame resolution and where the market is pushing to resolutions exceeding 4k (3840x2160 pixels) is that this produces an enormous amount of data. Consider what happens when a video file format uses 3 bytes per pixel at 1920x1080 resolution. It takes about 5.93
megabytes to represent a single frame of video:
At this rate, one second of video takes up about 177.9 megabytes of data (1423 Mbps); one minute goes well over ten gigabytes. This is impractical to transmit and store. Currently, one of AT&T's top fiber optic internet plans (Internet 1000) supports download speeds of, "500-940Mbps [where one can] Download a 90-min. HD movie in under 7 seconds" (AT&T, 2019). The problem with code described is that it exceeds the data rate of even a high-speed internet connection. It is therefore impossible to stream the video just described in real time over this connection. At the low end of this connection, it could take almost three seconds to download one second of video. Still, AT&T claims that an hour and a half of HD video can be downloaded in under 7 seconds. This can be achieved only because a video signal can be compressed to a lower data rate.
Video compression algorithms can be broadly classified as either lossless or lossy. Lossless denotes zero loss in quality while reducing the data rate to some degree. Lossy denotes a certain amount of loss in signal quality while compressing data rate to a much greater degree than lossless compression. In 1948, "[Claude] Shannon demonstrated that no coding scheme can code the source losslessly at a rate lower than its entropy" (Bull, 2014, p. 94). This is known as: the Entropy Limit. This means that a digital video signal requires a minimum amount of data to represent a signal with zero loss in quality. Shannon's equation proves that it takes a minimum of 3 bytes of computer data to represent each of the 16,777,216 values in the RGB Color Model when each color value has an equal probability of occurring. Shannon used the variable, H, to denote entropy:
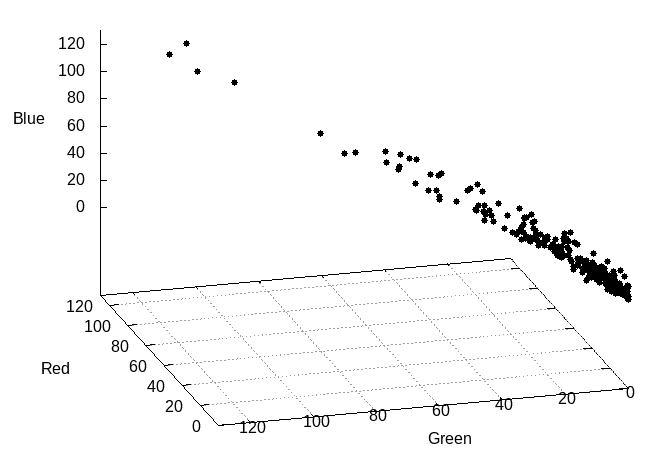
To losslessly encode n different colors per pixel that each have an equaprobable chance of being selected requires a code of n symbols. 24 bits can represent exactly 16,777,216 or 224 distinct color values. But, "[A]lthough [Shannon's equation] provides a lower bound on the compression that can be achieved when directly coding statistically independent pixels, it breaks down when the pixels of an image are correlated" (Gonzalez, 2018, p. 547). A 16x16 block of image data from Fig-3 is plotted in 3d space (where the x, y, and z axes denote red, green and blue values respectively) in Fig-4 and another angle in 2D space in Fig-5.
Fig-3: Halley's Comet crossing the Milky WayFig-4: A 16x16 pixel block from Fig-1 shows a linear correlation in the data.
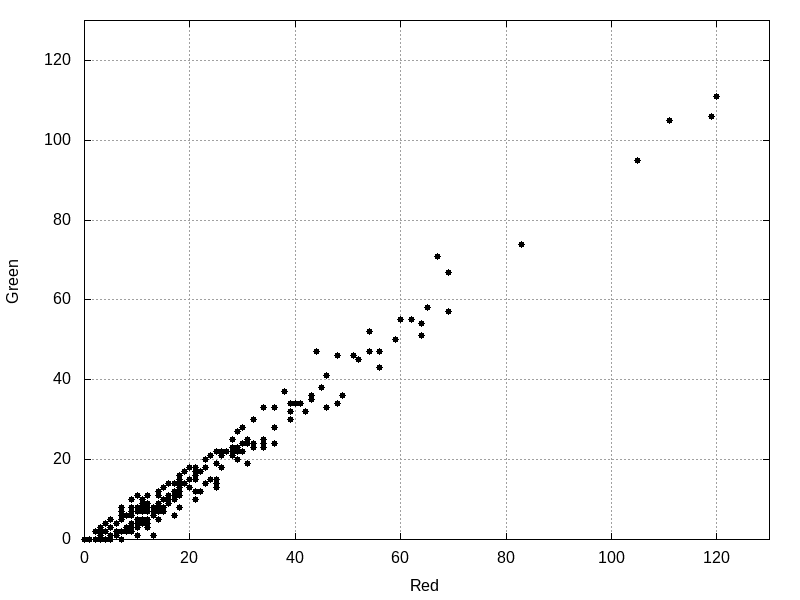
Both Fig-4 and Fig-5 show a linear correlation in the pixel data from Fig-3. Correlation is, "A measure of a tendency for two or more random variables to be associated" (Oxford, 2016, p. 123) and can be demonstrated by a line that best fits the data in a scatterplot like in Fig-4 and Fig-5. The data in Fig-5, "are positively linearly correlated, meaning that y [green pixel values] tends to increase linearly as x [red pixel values] increases" (Weiss, 2012, p. 656-657). Although Dr. Shannon defined a lower bound, there can also be an upper bound, denoting the fewest number of symbols needed to achieve lossless compression. Fig-5 shows that many pixels in this block are in the range:
0 ≤ x ≤ 40 and 0 ≤ y ≤ 40
Beyond this range, there are fewer pixels. Huffman Encoding is a type of Entropy Coding that exploits the fact that many pixel color values in an image occur far more often than others. It is a process whereby a shorter code is assigned to more frequently-occurring symbols and a longer code is assigned to less frequently-occurring symbols. Video and still-image compression file formats contain a Huffman Table, which contains two columns, one with pixel values and another with the probability that the pixel in the corresponding row will occur in the image. Next, this table is sorted, descending, by the probability column and used to progressively build a tree data structure, called a Huffman Tree. This is then used in the creation of a variable-size code where more frequently-occuring pixels in the image get a shorter code than less frequently-occuring ones. Lastly, the Huffman Table with pixel values and their corresponding codes are written to a file so
that the decoder can interpret what pixel value each code represents. The Huffman Table adds some data to the file, but even with this added data, Huffman Encoding results in significant compression to the video file.
Fig-5: A 16x16 pixel block from Fig-1 shows a linear correlation in the data; viewed, here, in 2 dimensions.
Huffman Encoding establishes an upper bound to Shannon's lower bound and achieves a reduction in data rate with zero loss in signal quality; a lossless compression. At the entropy limit, there will be zero loss in perceptual quality, since no data is discarded using entropy coding. An entropy coding stage is a valuable addition to any system that is built to compress video. It is used in the encoder in Fig-17, which will be brought up later in this paper and also is used in many other video encoding systems. However, "[L]ossless compression methods [like entropy coding], if used in isolation, are typically restricted to [compression] ratios around 4:1" (Bull, 2014, p. 216). So for around every 4 pixels input into an encoder, one is output. This paper began describing a model that took 177.9 megabytes of data (1423 Mbps) to represent one second of video. Entropy coding can bring this data rate down to about 44.5 megabytes per second (355.8 Mbps). This is a good start that enables a real-time video data stream even during the slow periods described in AT&T's ad (500 Mbps), mentioned earlier. VoIP sites like Skype.com would require this kind of compression at minimum to make video data available in real time. This still does not come close to the 7 seconds of HD video downloaded in 1 second promised by AT&T's ad. These data rates are still possible, but go beyond the compression ratio of lossless compression. To achieve these kinds of results, the signal must be approximated by removing data. When removing certain data, the more unnoticeable it is to viewers, the better. This will allow for greater compression ratios and lower data rates at the expense of some degree of quality loss. One way of achieving this objective is through the removal of spatial frequencies in the image that are perceptually less noticable. Before this can happen, an image must first be converted from the form it is currently in, an array of pixel intensity values or a spatial domain, to a frequency domain.
Transform Coding describes the conversion of an image from a spatial domain to a frequency domain. Before a frame of video begins the transform stage, it first enters a process whereby it is broken into blocks, called, segmentation. A frame is input into the segmentation stage as a full image and is output as a number of square blocks of NxN pixels. These blocks are next provided as input to the transform stage so that they can be further broken up into component spatial frequencies. This is done for the purpose of discarding data, in another stage of compression, that is less perceptible to the human visual system. What has been discovered is that, “Most 2-D intensity arrays contain information that is ignored by the human visual system and/or extraneous to the intended use of the image. It is redundant in the sense that it is not used” (Gonzalez, 2018, p. 540). There are many different ways to achieve the objective of breaking an image into component spatial frequencies, but the main idea is best expressed by the Spatial-Frequency Theory of Vision. This theory, “[I]s based on two physical principles: First, that any visual stimulus can be represented by plotting the intensity of the light along lines running through it; and second, that any curve, no matter how irregular, can be broken down into constituent sine waves by Fourier analysis” (Pinel, 2013, p. 136). The visual stimulus, in this instance, is the change in the light intensities of pixels running from left-to-right as horizontal rows that make up a video frame. There are many different transforms, including: the Discrete Sine Transform, the Discrete Fourier Transform, the Karhunen Loeve Transform, and the Walsh-Hadamard Transform. The one considered in this paper uses cosine waves, which are only different in phase from the sine waves used by Fourier analysis, mentioned by Pinel in the previous quote.
The type of transform discussed in this section is called the Discrete Cosine Transform (DCT), which is used in Google's VP9 video compression, JPEG still-image compression, MPEG video compression, and Apple's ProRes video compression. In this section, blocks of size 4x4 will be considered, however DCT has been implemented to transform blocks of size 8x8, 16x16, 32x32 and other multiples of 8x8 blocks. Suppose that Fig-6, below, is the current frame being encoded and that it has been broken up into a number of 4x4 blocks, one of which is Fig-7. Fig-8 describes the pixel values from Fig-7 numerically, where the image is described as a matrix of shades of the green color channel. This matrix will be provided as input to the transform stage. Notice that twelve out of the sixteen values in Fig-8 (75%) fall within the range of 137-201, a range just slightly above 25% of the 256 possible values. This demonstrates that although a region of high contrast has been chosen in Fig-7, an area between the black sky and the bright gray (almost white) moon, the pixel data that is being processed is spatially correlated. "Because the pixels of most 2-D intensity arrays are correlated spatially (i.e., each pixel is similar to or dependent upon neighboring pixels), information is unnecessarily replicated in the representations of the correlated pixels" (Gonzalez, 2018, p. 540). The Discrete Cosine Transform is used to decorrelate this data.
Fig-6: the current frame being processed by an enocderFig-7: A 4x4 block taken from Fig-6's green color channel.Fig-8: Fig-7, before DCT is applied.Fig-9: Fig-7 after DCT is applied; DCT coefficients result
For the region of 4x4 pixels in Fig-8, "[W]e can transform this into a set of... [16] DCT coefficients [Fig-9], which is the spatial frequency representation of the [4x4] region of the image [from Fig 8]" (Parker, 2017, p. 311). The DCT coefficients that are being referred to from Fig-9 denote the frequency, the number of times that one of the DCT basis functions in Fig-10 appears in the original 4x4 block (Fig-8). So if each of the coefficients produced by the DCT in Fig-9 is individually multiplied by its respective basis function in Fig-10 and then all of these numbers are added together, we get exactly the original block, Fig-8, back again. This means that the Discrete Cosine Transform is completely reversible. When moving from an image in a spatial domain to a frequency domain, the Forward DCT equation is used. When performing the opposite operation, the Inverse DCT equation, which is derived from the Forward DCT, is used. The DCT is completely reversible because there is no data being removed in the process. The only thing that is changing is the way that the data is being viewed.
In general, the Discrete Cosine Transform turns any NxN image block into a linear combination of NxN basis vectors. These basis vectors, expressed as images in Fig-10, can also be expressed as matrices. So a matrix or block of NxN pixels, B, can be expressed by N2 spatial frequencies, , where each frequency is multiplied by its respective basis vectors,
.
This describes a process whereby NxN numbers are input and NxN numbers are output. There is no compression of any kind happening in the transform stage. What is happening is that now that the image has been converted to the frequency domain, there is a basis to begin a discussion on removing spatial frequencies that are perceptually irrelevant and that can reduce the video signal's data rate at the same time. This all happens in the Quantization stage of compression.
Quantization
Although the Discrete Cosine Transform does not compress an image and it is completely reversible, spatial frequencies can be removed to achieve a lossy compression of the image. Quantization is a process by which a large set of numbers is mapped to a smaller set of numbers. It is a stage in the compression process where data is discarded and the signal is approximated. “Quantization is an important step in lossy compression; however [, unlike the DCT and the transform stage,] it is irreversible and causes signal degradation” (Bull, 2014, p.155). A simple example of quantization is if a set of integer pixel values from 0-255 were input into a quantizer and rounded to the nearest ten to produce an output set. With only the rounded values from the output set, it is impossible to go back and recover the original, input values. Likewise, when the Forward DCT is applied to an image block, spatial frequencies can be removed and the Reverse DCT can return the remaining spatial frequencies back to the original spatial block minus the removed frequencies. Fig-11a through Fig-11e demonstrate what it looks like to remove spatial frequencies from a block to varying degrees. A quantization parameter applied to a block denotes no change in the output block. As the quantization parameter increases in value, the numbers in the block become more uniform in value, but also represent the original input block less faithfully. Between Fig-11a through Fig-11b there is very little perceptual difference, however there is a small amount of compression between the two blocks. Fig-11a through Fig-11c all represent 16 pixels.
Fig-11a through Fig-11e represent 16 pixels with 13 through 9 symbols, respectively. As a block is represented with fewer symbols in a code, it becomes more and more flat until it converges on some value where every pixel in the block is equal to that value. Shannon's equation demonstrates that less and less information is present in each block as a fewer number of symbols are needed to represent the pixels in the block.
Fig-12a: 13 symbol representation.Fig-12b: 12 symbol representation.Fig-12c: 11 symbol representationFig-12d: 10 symbol representation
Some of the constituent cosine wave frequencies of a block that are output by the DCT are more important than others. "Essentially, the [human visual system] is more sensitive to lower spatial frequencies and less sensitive to high spatial-frequencies" (Bull, 2014, p. 42). Since this paper uses 4x4 blocks, there are 16 possible spatial frequencies output by the DCT from which to choose from, where frequency 1
describes the lowest and frequency 16 describes the highest spatial frequency. There are also spatial frequencies between these two values which correspond to all of the blocks in Fig-10. Fig-12a is the same uncompressed block from the moon image in Fig-7 and the same image that the previous example started with. In Fig-12b through Fig-12d, high spatial frequencies were removed from each block. There is little to no discernable difference between each block because mostly high frequency data was removed in an effort to bring the numeric pixel values close to each other. It takes the same quantity of data, 10 symbols, to represent both Fig-12d and Fig-11d. There is a great perceptual difference between Fig-11d and Fig-11a, but close to no perceptual difference between Fig-12d and Fig-12a. The first quantizer yields inferior results because it performs a simple rounding procedure across all spatial frequencies. The second quantizer carefully selected the most imperceptible frequencies possible. The benefit of the first quantizer is speed, but this came at the expense of quality. The benefit of the second quantizer is quality, but this came at the expense of speed. The second quantizer took into account the human visual system, whereas the first did not. The first indiscriminately rounded off all spatial frequencies according to a quantization parameter. The second quantizer barely touched any of the low spatial frequencies in the block. The result of this is that there is an apparent drop in overall light intensity in the output blocks for quantizer one (Fig-11), but this is not present in quantizer two's output blocks (Fig-12). Looking back at Fig-10 the concept becomes a little more clear. The frequency from the top left block, which denotes a completely flat frequency, was untouched by quantizer one. When this same frequency was rounded off by the first quantizer, it caused an overall, flat drop in the intensity of all pixels on the frequency that the HVS is most sensitive to. Moving down and right in Fig-10, the blocks increase in spatial-freqeuncy. The highest spatial-frequency is the bottom right block, which the human visual system is least sensitive to. Quantizer one utilized mostly frequencies from the bottom row of Fig-10. This demonstrates how, "[C]oefficients can be quantized... according to their perceptual importance" (Bull, 2014, p. Fig-10: 4x4 DCT Basis Vectors 134). This also demonstrates that it is possible to eliminate data that is hard for the human visual system to perceive, to thereby preserve the perceptual quality of an input digital video signal, and do all of this while reducing the overall quantity of data that makes up the signal.
The work performed by both quantizers reduced the number of symbols it took to represent a block. As a result, many encoders, including the one in Fig-16, choose a transform stage, followed by a quantization stage, followed lastly by an entropy coding stage. By the time that the encoder moves to entropy coding, the transform and quantization stages have eliminated the number of symbols that need to be accounted for in the block by bringing the numbers closer together. This makes entropy coding more efficient because these two steps have increased the probability that certain pixel values occur in a block. As a result, lossless compression methods such as, Huffman encoding with its variable-size code, can assign short codes to pixels with the highest probability of occurring and achieve higher compression ratios than the 4:1 compression ratio achieveable by lossless compression alone. The compression ratios that can be achieved are variable, depending on how much quality loss is acceptable for a particular application. The greater a signal is quantized, it contains less information, less data is needed to represent the signal, and the signal will contain less quality. Before quality is discussed, the next section discusses motion and compressing pixel data over time to achieve even greater levels of compression on a video signal. The section that follows this describes a method to incorporate human attentiveness to areas of the frame over time. To understand better what defines quality, consider first how frames change over time and how humans focus on different regions of interest in a frame over time.
Inter-Frame Compression
All compression methods that have been considered thus far have been intra-frame compression methods; that is, methods that consider compressing pixel data with respect to the area within the frame. This next section discusses an inter-frame compression method, or one that considers changes in pixel values with respect to time. Inter-frame compression considers the apparent motion created by a sequence of frames containing progressive, 2D projections of an array of light intensity values from a 3D environment. Just as spatial pixel data is correlated, "...natural video data is [also] correlated in time" (Bull, 2014, p. 259). There are many pixel blocks that do not change from frame-to-frame. Take video from a television news broadcast, for example, where the news anchor is talking, but there is a solid-color background behind them. There are potentially hundreds of pixel blocks in this video that do not change and running them repeatedly through the transform stage results in the performance of redundant work. Building a video encoder that can recognize this situation and encode a video without this redundant data results in a substantial reduction in the data rate of the output signal. The timing of recognizing this situation is also very important. The encoder can eliminate a large amount of processing overhead if it recognizes repeated blocks before a frame reaches the transform stage of compression for reasons described in the next paragraph.
Fig-8: Fig-7, before DCT is applied.Fig-9: Fig-7 after DCT is applied.Fig-13: Forward Discrete Cosine Transform Formula.
In the attempt to reduce the data rate of a digital video signal, the DCT, quantization, and entropy coding has been introduced, however, a substantial problem has also been created. Consider what is being asked of a computer when a Discrete Cosine Transform needs to be calculated on an 8x8 block. Also consider that blocks as large as 64x64 and 128x128 are common in video compression codecs such as AV1 and Google's VP9. Larger blocks require more calculations to be made than smaller blocks. The formula in Fig-13 is is the Forward DCT formula used to transform the block in Fig-8 to the block in Fig-9. For an 8x8 block (N = 4) this formula requires an element of the X matrix (Fig-8) and the two cosine terms in the equation to be added together a total of 64 times. Within each cosine term, a sequence of multiplication, addition, and division calculations need to be carried out; six altogether. Additionally, the DCT equation needs to be carried out for each element in an 8x8 matrix, which means it needs to be carried out 64 times per block. For an 8x8 block this all means that there will be about 16,400 calculations that need to be made for a single block. A standard 1920x1080 high definition pixel frame contains exactly 32,400 8x8 pixel blocks. This means that over 531 million calculations need to be made for one frame of video. The processing overhead for the computer is enormous, however, there are ways to simplify this algorithm so that many fewer calculations need to be performed. For instance, the term, 2N in Fig-13 should not be repeatedly multiplied when it can be calculated in advance. However, the question should be posed: does the DCT formula need to be applied to every block in every frame? The answer is: no, "...there is significant temporal redundancy present in most image sequences... [and] this is exploited in most compression methods, by applying motion compensated prediction, prior to transformation" (Bull, 2014, p. 76). The next paragraph describes a simple method of inter-prediction.
Fig-14: I-Frame or Intra-Frame.Fig-15: P-Frame or Predicted Frame.
Inter-Prediction is, "The process of deriving the prediction value for the current frame using previously decoded frames" (Grange, 2016, p. 9). To start this process out, the encoder must process every single block in a reference frame, called an Intra-Frame or an I-Frame. The encoder next processes only the blocks that change from the previous frame to create a Predicted-Frame or a P-Frame that now depends upon the previous I-frame to be completely decoded. An example of this process is in Fig-14 and Fig-15 which show two frames, taken a fraction of a second apart, where blocks do not change in pixel values from one frame to the next. Fig-14 is an I-frame, or a frame that contains all of the pixel data necessary to represent a frame of video. Fig-15 is a P-frame, or a frame that contains only the blocks that change from Fig-14. By encoding video data in this manner, the encoder processes many fewer blocks than it would if it had to encode every block in every frame. There is some overhead when the video is played back, in that when the video decoder reaches a P Frame, it must reference the previous I-Frame to fill in the blanks in the P-Frame. There also exists the problem that if data in an I-Frame becomes corrupted, this can corrupt a whole Group of Pictures. This corruption could be a transmission error when a video is sent out over the internet. Due to the high data rate of video transmission, a commonly-used OSI Model Transport Layer protocol, called User Datagram Protocol (UDP) does not retransmit lost data segments. If the I frame happens to be inside the lost segment that does not reach its destination, the P-Frames can not render a complete frame because they depend on the I-Frame. As a result, the viewer receives incomplete frames over some duration of time.
The benefit of using I-Frames and P-Frames is that a substantial quantity of data can be discarded, but the original data of the video can still be completely reconstructed. Fig-15 successfully discards at least 25% of the data in the frame. This can improve even further for videos with less motion. Although, "Motion can be a complex combination of translation, rotation, zoom, and shear" (Bull, 2014, p. 257) and the algorithms that encode motion can grow much more complex, the algorithm that was just outlined demonstates a straightforward and effective method of eliminating temporal redundancy in a video. Ultimately, "The goal is... to exploit both temporal and spatial redundancy when coding the video sequence" (Bull, 2014, p. 257). The next section will build off of this idea to consider how the human visual system is incorporated into this process. Viewers focus attention on spatial regions of their environment over time to the exclusion of other spatial regions. The next section describes how compression can be achieved by taking into consideration what human viewers focus on, and, more important for the purpose of compression, what is not being focused on.
Spatio-Temporal Saliency
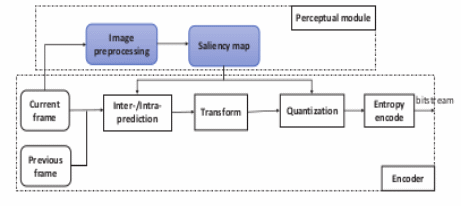
The video encoder proposed by Jiang, Song, Zhu, Katayama, and Wang adds what they term a, Perceptual module, to the system framework that has been considered by this paper thus far. Fig-16 includes modules for the current frame, inter-prediction, transform, quantization, and entropy coding stages. Most encoders implement a sequence of operations similar to this model and the signal leaves the encoder as a compressed bitstream or sequence of binary numeric values made available over time. Within the perceptual module, a saliency map submodule provides data to both the inter-prediction and quantization stages. Starting with a description of what saliency and a saliency map is, this section describes how research in video compression seeks to account for human visual perception variables that it did not consider in the past.
Fig-17: (a) A visual scene. (b) Saliency map of the scene.
Kimura et al. describe, "[S]aliency as a measure of attentiveness" (Kimura, Yonetani, Hirayama, 2013, p. 562). Saliency answers the question: What is the probability that a viewer is paying attention to a given area of a video frame at a particular point in time? That probability, a number between 0 and 1 (inclusive), is mapped to a corresponding region in a black and white frame referred to as a, saliency map. This map is generated using a video frame as input and helps the encoder to determine which regions of the image it would like to subject to more or less compression based on where viewers are looking in the video frame. In Fig-17a there is a frame which has been used to generate a corresponding saliency map in Fig-17b. In the saliency map, Fig-17: Perceptual Video Encoding Framework Fig-18: (a) A visual scene. (b) Saliency map of the scene. "Regions of greater visual salience are denoted by brighter regions" (Goldstein et al., 2017, p. 128). In Fig-17's example, the area of the sky, exluding the clouds, would be a good place for the quantization stage of compression to remove lower spatial-frequencies than it otherwise would in a highly salient region. Back in the section on quantization, it was noted that, "Essentially, the [human visual system] is more sensitive to lower spatial frequencies and less sensitive to high spatial-frequencies" (Bull, 2014, p. 42). As the human eye scans a video frame over time, attention to different spatial-regions change. Spatio-temporal salience denotes this change in attention over time. What does not change, however, is that the region that the eye has its attention on is most clearly perceived. The regions that are outside of this area of spatial salience are out of focus. Visual acuity, or, "[T]he ability to see details... is highest in the fovea; [of the human eye, and] objects that are imaged on the peripheral retina are not seen as clearly" (Goldstein et al., 2017, p. 41). It therefore stands to reason that since details, in the form of high spatial-freqencies, outside of salient regions are not perceived with clarity, they can be safely discarded.
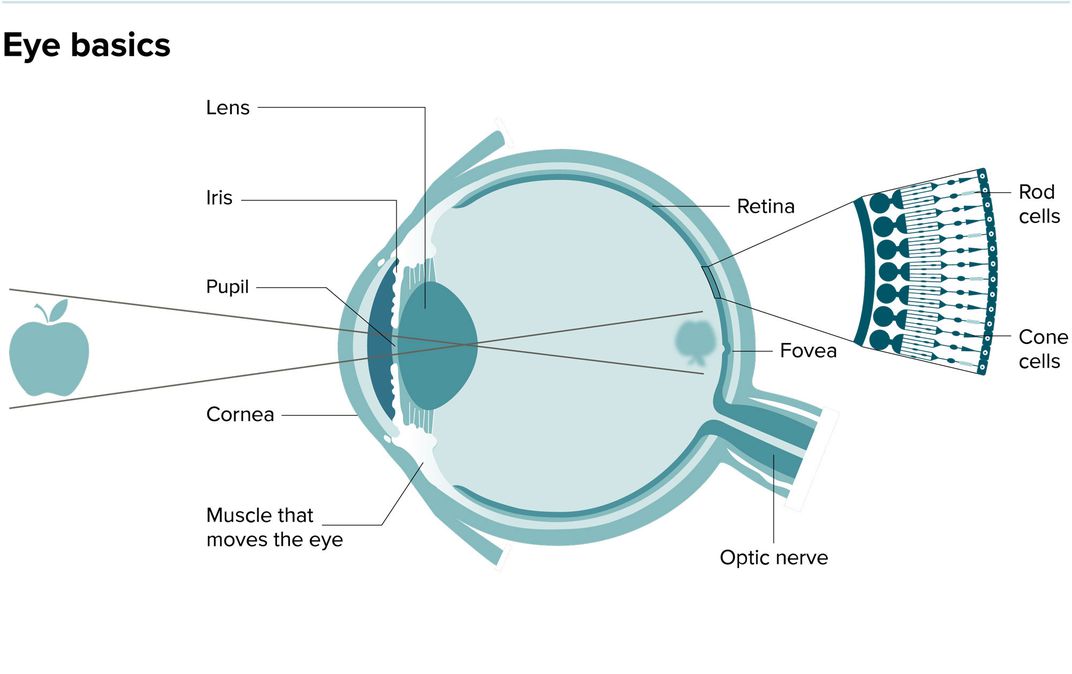
Fig-18: This illustration laying out the basic structure of the eye shows where the fovea- where images are rendered in high resolution- is situated.
In contrast, highly salient regions of an image, where there is a high probability that viewers will be paying attention to an area of the frame, a video encoder can choose to remove fewer spatial frequencies at the quantization stage. Likewise, in lower probability areas the choice can be made to discard more, and lower, spatial frequencies. As a result, less salient regions are encoded with lower quality than highly salient regions. The human visual system does not miss this loss in quality since human visual perception has been accounted for in the encoding process. There is little to no perceptual quality reduction while the overall data rate is reduced. One place that Jiang et al.'s proposed video encoder (Fig-16) provides a saliency map of the current frame to is the quantizer. The quantization stage is an important place for human perception to be accounted for since it is where the encoder discards data; another important place is during Inter-Frame Compression, where temporal saliency is considered.
The temporal aspect of saliency has to be accounted for as well. Just like the inter-prediction stage accounts for changes from frame-to-frame, the perceptual module must take into consideration how a viewer's attention will shift from frame-to-frame. It turns out that, "Motion is a very salient aspect of the environment, so it attracts our attention" (Goldstein et al., 2017, p. 173). This change in attention over time involves a viewer scanning and fixating their attention on different regions of a frame. "[C]ertain temporal events such as sudden changes in (parts of) image frames and the motions of objects would be significant cues for visual attention, which implies that the temporal dynamics of image features should be considered when modeling human visual attention" (Kimura et al., 2013, p. 567).
Spatio-temporal saliency accounts for not only where human visual attention is directed and when it is directed there, but also why it is likely to be directed to certain spatial regions over others. Motion is one reason why attention may be directed to a specific region, but other reasons include a scene being, "[M]arkedly different from... [its'] surroundings, whether in color, contrast, movement, or orientation... [, an observer's] knowledge of what is contained in typical scenes... [and also] observer interests and goals" (Goldstein et al., 2017, p. 127-129). Observer-interpretation of a scene is subjective and difficult to model with an algorithm, but the general point is for a computer to deliver high quality to regions that the human visual system deems to be important and lower quality elsewhere. In the regions that attention is likely to be directed; that is input to the encoder from the human visual system. When quality is output in these regions, that is output from the encoder to the human visual system. In this way, salience can be seen as an interface between a natural, biological system and an artificial, computer system. The interface is established by what Jiang et al. term the: perceptual module (Fig-16). In their paper, they discuss how, "A perceptual model based on the human visual system (HVS) can be integrated into the video coding framework to achieve a low bitrate with a high perceptual quality" (Jiang et al., 2019, p. 1). Algorithms that bring together these two natural and artificial systems in an effort to compress digital video data are collectively called, Perceptual Video Coding (PVC) Algorithms. PVC is a class of algorithms that seeks the optimal outcome of two competing objectives: the requirement of the human visual system for a quality video and the requirement of computer systems for a low bit rate so that this quality video can be efficiently moved over networks and stored on some physical medium. New research in the field is being driven by perception-based compression. Given that human visual perception is not completely understood by scholars in the field, which is the topic of the next section, there may very well be algorithms to manipulate video data that preserve quality and lower bit rate that have not yet been discovered.
Perceptual Video Quality
It has been discussed how quality is sacrificed to achieve greater compression levels and that, "[M]uch greater levels of compression are possible with a little loss of video quality" (Parker, 2017, p. 311). But how is perceptual quality defined and how is the degree of perceptual quality loss measured? Lossless compression algorithms define a point where it is known that there is no loss in quality because no data is discarded and the algorithms are reversible. Lossy compression algorithms are just the opposite; they discard data and they are irreversible. So how can the degree to which perceptual quality has been lost in a video signal be objectively known? In general, "Visual perception is highly complex, influenced by many confounding factors, not fully understood and difficult to model" (Bull, 2014, p. 318). In addition to this, scholars who study the topic of video compression disagree with regards to what defines quality. Most of the disagreement seems to come from the lack of ability to model the human visual system completely and mathematically. If it could be modeled in these two ways, there would be an objective basis on which to establish a definition to replace both subjective and incomplete, objective tests.
There are many different formulas used to measure image quality. These formulas, identified by their abbreviations, include: Peak Signal-to-Noise Ratio (PSNR), VSNR, VQM, SSIM, MOVIE, MAN, STMAD, and PVM. Each of these formulas take into account different variables in an attempt to model the human visual system (HVS) and assess how quality is perceived. "The near threshold and supra-threshold properties of the HVS were exploited by Chandler and Hemami in the Visual Signal-to-Noise Ratio (VSNR) still image metric" (Bull, 2014, p. 340). Dr. Chandler has degrees in both Biomedical and Electrical Engineering, according to the paper that he co-authored, entitled, VSNR: A Wavelet-Based Visual Signal-to-Noise Ratio for Natural Images (Chandler, Hemami, 2007). The Peak Signal-to-Noise Ratio, PSNR, is an older video quality metric, still in use today, that compares a source signal with a post-compression version of the same signal. PSNR also takes into account the image bit depth, or the range of colors that can be reproduced in an image. However, "[T]here is no perceptual basis for PSNR, [although] it does fit reasonably well with subjective assessments..." (Bull, 2014, p. 126). The primary difference that emerges when comparing PSNR with VSNR is that the latter takes into account the human visual system while the former does not.
Since the human visual system cannot be completely modeled, the degree of quality of a video signal can only be measured to a certain extent using objective metrics. There have also been attempts to assess video quality from a subjective standpoint. That is, researchers can simply ask a person or group of people to rate the quality of an image. Any discussion of subjective quality metrics must take into account how the viewing environment, sound quality, image size, and the like affect the viewer. There is also a weakness with subjective quality metrics and that is the lack of ability for many of these methods to provide real-time feedback to the encoder. "Quality assessments are increasingly needed in the encoding loop to make instantaneous RQO [Rate Quality Optimization] decisions about which coding modes and parameter setting to use for optimum performance given certain content and rate constraints" (Bull, 2014, p. 333). In other words, the encoder can determine if it is outputting good quality in real-time according to a well defined algorithm. Video quality assessment is far from being a secondary consideration to the encoding process; as more research is conducted, a module which assesses video quality may very well become a part of the encoding process. As a result, figuring out variables in the human visual system that have not been taken into account in the quality-assessment process is an important area of research in video compression.
Until a suitable definition of quality is found, sometimes the use of compression is avoided altogether. What is considered acceptable quality for an online video is most likely not acceptable for medical imaging applications or court evidence. Compression methods can introduce artifacts, or distortions, into the video particularly at block edges after a Discrete Cosine Transform has been applied to a video. A suitable definition for quality is important because it helps researchers know what they are progressing towards and how they will be able to know when they get there. For now, the definition of quality is subjective; a human subject knows what good quality looks good, but it has not been defined in an objective sense. One thing that is known is that the context in which a video is viewed is important. "Several factors about the viewing environment will influence the perception of picture quality. These include: Display Size... [,] Display brightness and dynamic range... [,] Display resolution... [,] Ambient lighting... [,] viewing distance [and] Audio quality" (Bull, 2014, p. 320). With this idea in mind, this paper proposes an encoding process based on the viewing environment, called, Contextual Video Encoding.
Contextual Video Encoding
The general idea of having content adapting to devices is not new and has been implemented in web development with some degree of success. Many major websites such as YouTube, Yahoo, Ebay, and Google have mobile and desktop versions of their website, for example. Their sites adapt to different screen sizes. "HTML has a set of basic tags, mostly defining format rather than content" (Oxford, 2016, p. 258) and with its video tag, <video>, it can send a different videos to a client browser based on the type of decoder that is installed on the client's machine. CSS is, "A method of specifying the appearance of HTML..." (Oxford, 2016, p. 129) so a web page can render text and images on the screen differently depending on a computer's screen size by separating the content of a page from its style. What if a video encoder could use environmental parameters to alter a video to adapt to varying user viewing environments, and thereby discover ways to further compress a video?
Fig-19: Screen size is measured by a line from the bottom left of the screen to the top right.Fig-20: Letter dimensions from the Snellen Chart.
Video content is delivered to a wide range of devices and viewing environments ranging from smart phones to desktop computers and televisions to home theater systems. Viewers observe these videos at varying proximities. Videos sent to different type screens could be compressed to differing degrees depending on the parameters of display: width, height, screen size, and viewer proximity to the device. These are some variables that can be used as encoding parameters for a particular device, which would first have to be gathered from a user. Next, the video would have to be processed using these parameters. Using the display width (w) and height (h) in pixels, the pixel distance of the diagonal line that runs through the screen can be calculated using the Pythagorean Theorm. Knowing the screen size, in inches, it is possible to calculate the pixel density or spatial resolution. "[S]patial resolution is a measure of the smallest discernible detail in an image... [which can be measured in] dots (pixels) per unit distance..." (Gonzalez, 2018, p. 71). Below, the screen size, in units of pixels, is divided by the screen size, in units of inches (si) to obtain pixels per inch.
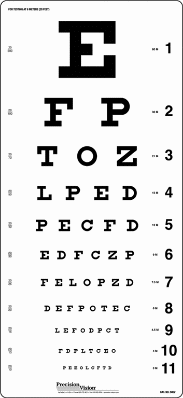
Fig-21: Snellen Chart
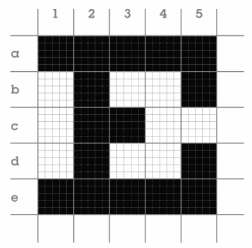
Now that spatial resolution of a video display is defined, both in terms of pixels and inches, this paragraph will return to the idea of, visual acuity, which is tested by a Snellen Chart. Herman Snellen defined the 5x5 square Fig-20: Screen size is measured by a line from the bottom left of the screen to the top right. letter size on his chart as, "[T]he distance in meters (feet) at which the letter subtends 5 min of arc" (Bababekova, Rosenfield, Hue, Huang, 2011, p. 796). In other words, the letter size equals to the size of an arc formed by drawing a point, S, and a 5 minute (5/60 of a degree) angle from point S over some distance, d, to the letter. When a person's visual acuity is checked, the test is to see if they can read letters that most people can read standing 20 feet away from the Snellen Chart. Since not all eye doctors have the ability to have 20 feet of distance between their patient and the chart, the size of the letters and the chart can be adjusted by altering the variable for distance. If a patient can read at least half of the letters in line number 8 of Fig-22 from a certain distance, d, that patient is said to have 20/20 vision. So, refering to Fig-20, it can be demonstrated that the height and width of this letter, n, is:
therefore
and
feet or
inches
Fig-22: Distance from a subject to a letter on a Snellen chart.
It can be concluded that the area of the letter that a person with 20/20 vision can perceive is 0.12 square inches. If they can not read this, corrective lenses are used to bring their vision to this point. As the letters at the bottom of Fig-22 get smaller, it gets easier to confuse one letter with another. The letter, E, as it gets smaller, can begin to look like a, D. In Fig 21, if block 3c moved over to the empty space in 5c, the letter, E, would look even more like a, D, as it gets smaller. This gap of white space, makes up an area of critical detail in the letter, as, "Letters are constructed usually on a 5 x 5 grid so that the size of the critical detail (each gap width) subtends 1/5th of the overall height" (Sushma, 2017). When this critical detail is lost, acuity, or, "[T]he ability to see details" (Goldstein et al., 2017, p. 41) breaks down.
Visual acuity, "[C]an [also] be measured by the use of... a pattern of parallel vertical dark bars equal in width and separated by bright bars of the same width. As the dark and bright bars are made narrower, there comes a point when an observer is no longer able to... distinguish it from a uniform field of the same average brightness" (Bruce, Green, Georgeson, 2010, p. 14). Also, as a user gets farther away from a display, higher frequency spatial regions of the image become less important. This idea can be seen by viewing the constrast sensitivity chart in Fig-23. One can observe that at different viewing distances, the high-spatial-frequency data to the right of the chart ranges from discernible to indiscernible. The critical region (white space) is unable to be resolved by the viewer as proximity to the chart increases. Therefore, this paper proposes an algorithm whereby these spatial-freqencies are discarded in the quantization stage based on their perceptual irrelevance. As spatial frequencies become less discernible to the viewer, based on viewer proximity to the display, spatial frequencies become more irrelevant to the encoder and can be discarded. This leads to a progressive lowering of the data rate in direct proportion to a viewer's lowering ability to resolve the change in spatial-frequency.
Fig-23: Contrast Sensitivity Function.
Using this method, which will be termed, Contextual Video Encoding, videos that are sent to small screens, such as smartphones, could be compressed to a much greater degree than videos sent to large televisions with no perceptual quality loss. This would also allow faster transmission of video data to mobile devices that rely exclusively on wireless connections. Processing of the video Fig-24: Contrast Sensitivity Function would be faster, improving the mobile device's multitasking capabilities. It would also allow for more efficient storage of video data on mobile devices with smaller secondary storage options. Contextual Video Encoding could also consider viewer-proximity to the device as a range. An example of this is, smartphone and tablet users can stream a mobile version of a video encoded for a viewing proximity of 1 to 3 feet. Television users can have a video option encoded for a viewing proximity of maybe 5-10 feet or more. In summary, Contextual Video Encoding is a type of Perceptual Video Encoding that considers the viewing environment in the video compression framework to achieve a lower video data rate while maintaining perceptual quality. Other factors, in addition to what was mentioned, may also be able to be accounted for in the future including, "Display brightness and dynamic range… [,] Ambient lighting... [and] Audio quality" (Bull, 2014, p. 320). For now, the contextual encoding of video data based on viewer-proximity to the display seems like it yields the best results of the factors considered.
Conclusion
Digital video compression accounts for human visual perception in many different ways. This paper explored how traditional video encoders account for human trichromatic vision, how pixels are grouped and perceived as a complete frame, and how the perception of motion is created with a phenomenon known as, apparent motion. It went on to discuss the concept of entropy coding and how video can be compressed with no loss in quality. This was followed by how certain spatial frequency data could be discarded from a video frame without a perceptible loss in image quality. When it is considered how a video is more than more than just a sequence of still fames and how, "The whole is different than the sum of its parts, ... [it is realized that] the perceptual system creates the perception of movement where there actually is none" (Goldstein et al., 2017, p. 99). When looking at a video with respect to time and considering the inter-prediction of video data, entire blocks of pixel data can be removed when these blocks repeat themselves from frame-to-frame. It was also described how spatio-temporal salience can be used to output higher quality for regions of a frame that have a greater probability of holding human visual attention. "It is argued that perception-based compression techniques can improve video quality and that a new rate-quality optimization approach is required if we are to efficiently and effectively code the immersive formats of the future" (Bull, 2014, p. 451). This paper proposed, Contextual Video Encoding, a consideration of environmental variables to encode a video with high perceptual quality, while lowering the data rate necessary to reproduce the signal.
As more variables are considered, the model of the human visual system becomes more complete, but it is still objectively complex and currently beyond the ability of human beings to model in a complete, mathematical way. It was not until 1948, with Claude Shannon's paper, A Mathematical Theory of Communication, that it became known that information, including the images that we see in the world around us, can be measured. Our eyes and brain have the ability to detect, process, and store this information. Yet, despite the fact that we observe the world through our eyes and process the information with our brain, we do not fully understand the biological system by which this takes place. Much less is our ability to model it artificially. The human visual system is also subjectively powerful in its capacity to invoke strong emotions, to remind us of the past, and capture moments in time. When we finally understand the human visual system and how to model it, we will only then be able to truely, objectively see the world.
Comment
List of Tables and Figures
Fig-1 Complete video frame (DeMaria, 2019)
Fig-2 Zoomed in to Fig-1 to show individual pixels (DeMaria, 2019)
Fig-3 Halley's Comet crossing the Milky Way-- April 8/9, 1986. (1986). Retrieved from http://web.b.ebscohost.com.resources.njstatelib.org/ehost/detail/detail?vid=2&sid=67895226-71a9-44b2-9a54-07e99e4 6f06f@pdc-v-sessmgr03&bdata=JnNpdGU9ZWhvc3QtbGl2ZQ==#AN=imh723456&authdb=imh&db=aph
Fig-4 A 16x16 pixel block from Fig-3 shows a linear correlation in the data.
Fig-5 A 16x16 pixel block from Fig-3 shows a linear correlation in the data; viewed, here, in 2 dimensions.
Fig-6 The current frame being processed by an encoder (DeMaria, 2019)
Fig-7 A 4x4 block taken from Fig-6's green color channel (DeMaria, 2019)
Fig-8 Fig-7, before DCT is applied (DeMaria, 2019)
Fig-9 Fig-7 after DCT is applied; DCT coefficients result (DeMaria, 2019)
Fig-12 (a) 13 symbol representation (b) 12 symbol representation (c) 11 symbol representation (d) 10 symbol representation (DeMaria, 2019)
Fig-13 Forward Discrete Cosine Transform Formula (Richardson, 2008, p. 46)
Fig-14 I-Frame or Intra-Frame (Romero, 2018)
Fig-15 P-Frame or Predicted-Frame (Romero, 2018)
Fig-16 Perceptual Video Encoding (Jiang et. al., 2019, p. 3)
Fig-17 (a) A visual scene. (b) Saliency map of the scene. (Goldstein et al., 2017, p. 128)
Fig-18 This illustration laying out the basic structure of the eye shows where the fovea—where images are rendered in high resolution—is situated. (Vernimmen, 2019)
Fig-20 Letter dimensions from the Snellen Chart. (2015). Photograph retrieved from https://www.gizmodo.co.uk/2015/09/examining-thetypographic-history-of-eye-charts/
Fig-21 Snellen Chart. (2019). Photograph retrieved from https://www.precision-vision.com/wpcontent/uploads/2019/06/c501a702ef05e90d163a1eeeb1633357_XL.jpg.
Fig-22 Distance from a subject to a letter on a Snellen Chart (DeMaria, 2022)
Fig-23 Contrast Sensitivity Function. (Bull, 2014, p. 32)
Works Cited
AT&T Internet Services & Plans - AT&T ® Official Site. (n.d.). Retrieved November 13, 2019, from https://www.att.com/internet/internet-services.html.
Bababekova, Y., Rosenfield, M., Hue, J. E., & Huang, R. R. (2011). Font Size and Viewing Distance of Handheld Smart Phones. Optometry and Vision Science, 88(7), 795-797. doi: 10.1097/opx.0b013e3182198792
Bull, D. R. (2014). Communicating Pictures: A Course in Image and Video Coding (1st ed.). Oxford: Academic Press.
Chandler, D., & Hemami, S. (2007). VSNR: A Wavelet-Based Visual Signal-to-Noise Ratio for Natural Images. IEEE Transactions on Image Processing, 16(9), 2284-2298. doi: 10.1109/tip.2007.901820
Goldstein, E. B., & Brockmole, J. R. (2017). Sensation and Perception (10th ed.). Boston: Cengage Learning.
Gonzalez, R. C., & Woods, R. E. (2018). Digital Image Processing (4th ed.). New York, NY: Pearson.
Grange, A., de Rivaz, P., & Hunt, J. (2016). PDF. VP9 Bitstream & Decoding Process Specification Version 0.6
Jiang, X., Song, T., Zhu, D., Katayama, T., & Wang, L. (2019). Quality-Oriented Perceptual HEVC Based on the Spatiotemporal Saliency Detection Model. Entropy, 21(2), 1-12. doi: 10.3390/e21020165
Kimura, A., Yonetani, R., & Hirayama, T. (2013). Computational Models of Human Visual Attention and Their Implementations: A Survey. IEICE Transactions on Information and Systems, E96.D(3), 562-578. doi: 10.1587/transinf.e96.d.562
Oxford University Press. (2016). A Dictionary of Computer Science (7th ed.).
Parker, M. A. (2017). Digital Signal Processing 101 everything you need to know to get started (2nd ed.). Oxford: Newnes, an imprint of Elsevier.
Pinel, J. P. J., & Barnes, S. J. (2018). Biopsychology (9th ed.). Harlow: Pearson.
Rahali, M., Loukil, H., & Bouhlel, M. S. (2017). The Improvement of an Image Compression Approach Using Weber-Fechner Law. Advances in Intelligent Systems and Computing Intelligent Systems Design and Applications, 239-249. doi: 10.1007/978-3-31953480-0_24
Richardson, I. E. G. (2008). H.264 and Mpeg-4 Video Compression: Video Coding for Next Generation Multimedia. Chichester: John Wiley & Sons.
Romero, A. (2018, March 27). What is Video Encoding? Codecs and Compression. Retrieved November 19, 2019, from https://blog.video.ibm.com/streaming-video-tips/what-is-video-encoding-codecs-compression-techniques/.
Schneider, G. M., & Gersting, J. L. (2013). Invitation to Computer Science (6th ed.). Australia: Cengage Learning.
Shannon, C. E. (1948). A Mathematical Theory of Communication. The Bell System Technical Journal, 27, 1-55. doi: 10.1109/9780470544242.ch1
Sushma. (2017, October 5). How to Construct a Visual Acuity Chart? Retrieved November 21, 2019, from http://optometryzone.com/2016/11/10/visual-acuity-chart/.
Vernimmen, T. (2019, June 13). Our Eyes Are Always Darting Around, So How Come Our Vision Isn't Blurry? Retrieved November 20, 2019, from https://www.smithsonianmag.com/science-nature/our-eyes-are-always-darting-around-s-not-how-we-see-world180972414/.
Weiss, N. A. (2012). Introductory Statistics (9th ed.). Boston, MA.: Addison-Wesley


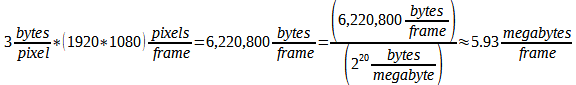
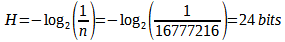


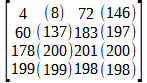
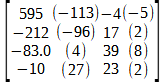

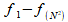
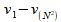 .
.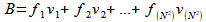









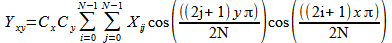




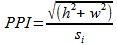
 therefore
therefore
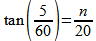 and
and
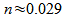 feet or
feet or
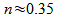 inches
inches

